10) Writing unit tests and running from anywhere on your machine¶
Related references:
- https://docs.python-guide.org/writing/tests/
- https://jeffknupp.com/blog/2013/12/09/improve-your-python-understanding-unit-testing/
- https://docs.python.org/3/library/unittest.html
We always want to test that our program works. Last time, we did that manually–I looked at the output and saw it was what I expected and wanted. We also talked about the need to automate tests, so we can be sure that, as we add more functionality, we don’t accidentally break something. This will also allow us to check that our program behaves as desired on multiple architectures. Today, we’ll discuss how to do so.
Writing tests for Python is much like writing tests for your own code.
Tests need to be thorough, fast, isolated, consistently repeatable, and
as simple as possible. We try to have tests both for normal behavior and
for error conditions. Tests live in the tests directory, where every
file that includes tests has a test_ prefix.
What is meant by unit testing?¶
It is testing small units of code, e.g. individual functions, to help isolate the location of the error.
In addition, I always test the “main” function to make sure individual units connect correctly.
unittest is also a test module in the Python standard library.
Creating test cases is accomplished by subclassing unittest.TestCase
(see below)
Examples of types of errors to look for¶
- Syntax errors: often checks that the user typed in a valid argument, and gives a useful error message if such a mistake is caught.
- Logical errors: when the algorithm used is not correct (either originally, or error created upon later editing of the code)
- Unexpected input/edge cases: e.g. a program is only meant to work with positive values (e.g. a zero is entered and a log will be taken)
What type of error does the test below check for?
In [1]:
# A very basic unittest
import unittest
def fun(x):
return x + 1
class MyTest(unittest.TestCase):
def test(self):
self.assertEqual(fun(3), 4)
The heart of the test is the assertion step at the end. There are many options, more even than those listed below. There are further notes on how all the following work at https://docs.python.org/3/library/unittest.html.
| Method | Checks that |
|---|---|
| assertEqual(a, b) | a == b |
| assertNotEqual( a, b) | a != b |
| assertTrue(x) | bool(x) is True |
| assertFalse(x) | bool(x) is False |
| assertIs(a, b) | a is b |
| assertIsNot(a, b) | a is not b |
| assertIsNone(x) | x is None |
| assertIsNotNone (x) | x is not None |
| assertIn(a, b) | a in b |
| assertNotIn(a, b) | a not in b |
| assertAlmostEqu al(a, b) | round(a-b, 7) == 0 |
| assertNotAlmost Equal(a, b) | round(a-b, 7) != 0 |
| assertGreater(a , b) | a > b |
| assertGreaterEq ual(a, b) | a >= b |
| assertLess(a, b) | a < b |
| assertLessEqual (a, b) | a <= b |
| assertCountEqua l(a, b) | a and b have the same elements in the same number, regardless of their order |
Generally, the functions we are testing will be in a different file than the tests. I’ve set up tests for our sample arthritis project (https://github.com/team-mayes/arthritis_proj_demo). Let’s walk through those tests to get a feel for the types of tests we want to make.
First, note that I’ve reorganized my folders a little bit, separating
out tests and making a subfolder with files for testing the script
data_proc.py. I like to have a separate test for each script, and a
separate folder for files for testing that script.
Screen shot
Now let’s look at test_data_proc.py. As usual, the beginning
includes imports of libraries. Not that we have to import the script
that we want to test.
In [2]:
"""
Unit and regression test for data_proc.py
"""
import errno
import os
import sys
import unittest
from contextlib import contextmanager
from io import StringIO
import numpy as np
import logging
from arthritis_proj.data_proc import main, data_analysis
The logging library is helpful to log or perform certain actions
only under certain conditions. You’ll see how this is used in the tests
below.
In [3]:
# logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
DISABLE_REMOVE = logger.isEnabledFor(logging.DEBUG)
To refer to where particular files are, we want to use relative paths only, as we want these tests to work on many diffrent machines. What do you think the following lines do?
In [4]:
CURRENT_DIR = os.path.dirname(__file__)
MAIN_DIR = os.path.join(CURRENT_DIR, '..')
TEST_DATA_DIR = os.path.join(CURRENT_DIR, 'data_proc')
PROJ_DIR = os.path.join(MAIN_DIR, 'arthritis_proj')
DATA_DIR = os.path.join(PROJ_DIR, 'data')
SAMPLE_DATA_FILE_LOC = os.path.join(DATA_DIR, 'sample_data.csv')
# Assumes running tests from the main directory
DEF_CSV_OUT = os.path.join(MAIN_DIR, 'sample_data_stats.csv')
DEF_PNG_OUT = os.path.join(MAIN_DIR, 'sample_data_stats.png')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-4-eee6dc89282f> in <module>()
----> 1 CURRENT_DIR = os.path.dirname(__file__)
2 MAIN_DIR = os.path.join(CURRENT_DIR, '..')
3 TEST_DATA_DIR = os.path.join(CURRENT_DIR, 'data_proc')
4 PROJ_DIR = os.path.join(MAIN_DIR, 'arthritis_proj')
5 DATA_DIR = os.path.join(PROJ_DIR, 'data')
NameError: name '__file__' is not defined
That does it for our preamble. Now I’ve defined a helper function that
will be used by the tests below it. (FYI, as described on
https://docs.python.org/3/library/errno.html, errno.ENOENT is a
standard error message that means No such file or directory. Any
questions on what this function does?
In [5]:
def silent_remove(filename, disable=False):
"""
Removes the target file name, catching and ignoring errors that indicate that the
file does not exist.
@param filename: The file to remove.
@param disable: boolean to flag if want to disable removal
"""
if not disable:
try:
os.remove(filename)
except OSError as e:
if e.errno != errno.ENOENT:
raise
Now let’s get to the tests themselves, going through each line to see what they do:
In [6]:
class TestMain(unittest.TestCase):
# These tests make sure that the program can run properly from main
def testSampleData(self):
# Checks that runs with defaults and that files are created
test_input = ["-c", DEFAULT_DATA_FILE_LOC]
try:
if logger.isEnabledFor(logging.DEBUG):
main(test_input)
# checks that the expected message is sent to standard out
with capture_stdout(main, test_input) as output:
self.assertTrue("sample_data_stats.csv" in output)
self.assertTrue(os.path.isfile("sample_data_stats.csv"))
self.assertTrue(os.path.isfile("sample_data_stats.png"))
finally:
silent_remove(DEF_CSV_OUT, disable=DISABLE_REMOVE)
silent_remove(DEF_PNG_OUT, disable=DISABLE_REMOVE)
class TestMainFailWell(unittest.TestCase):
def testMissingFile(self):
test_input = ["-c", "ghost.txt"]
if logger.isEnabledFor(logging.DEBUG):
main(test_input)
with capture_stderr(main, test_input) as output:
self.assertTrue("ghost.txt" in output)
capture_stdout and capture_stderr called functions at the bottom
of the file. Don’t worry about understanding each line of the bellow.
The main point is that these allow any messages sent to standard out or
standard error, respectively, to be captured as strings.
In [7]:
# Utility functions
# From http://schinckel.net/2013/04/15/capture-and-test-sys.stdout-sys.stderr-in-unittest.testcase/
@contextmanager
def capture_stdout(command, *args, **kwargs):
# pycharm doesn't know six very well, so ignore the false warning
# noinspection PyCallingNonCallable
out, sys.stdout = sys.stdout, StringIO()
command(*args, **kwargs)
sys.stdout.seek(0)
yield sys.stdout.read()
sys.stdout = out
@contextmanager
def capture_stderr(command, *args, **kwargs):
# pycharm doesn't know six very well, so ignore the false warning
# noinspection PyCallingNonCallable
err, sys.stderr = sys.stderr, StringIO()
command(*args, **kwargs)
sys.stderr.seek(0)
yield sys.stderr.read()
sys.stderr = err
Separately, the tests below checked that the function
data_analysis() behaves as expected.
In [8]:
class TestDataAnalysis(unittest.TestCase):
def testSampleData(self):
# Tests that the np array generated by the data_analysis function matches saved expected results
csv_data = np.loadtxt(fname=SAMPLE_DATA_FILE_LOC, delimiter=',')
analysis_results = data_analysis(csv_data)
expected_results = np.loadtxt(fname=os.path.join(TEST_DATA_DIR, "sample_data_results.csv"), delimiter=',')
self.assertTrue(np.allclose(expected_results, analysis_results))
def testSampleData2(self):
# A second check, with slightly different values, of the data_analysis function
csv_data = np.loadtxt(fname=os.path.join(TEST_DATA_DIR, "sample_data2.csv"), delimiter=',')
analysis_results = data_analysis(csv_data)
expected_results = np.loadtxt(fname=os.path.join(TEST_DATA_DIR, "sample_data2_results.csv"), delimiter=',')
self.assertTrue(np.allclose(expected_results, analysis_results))
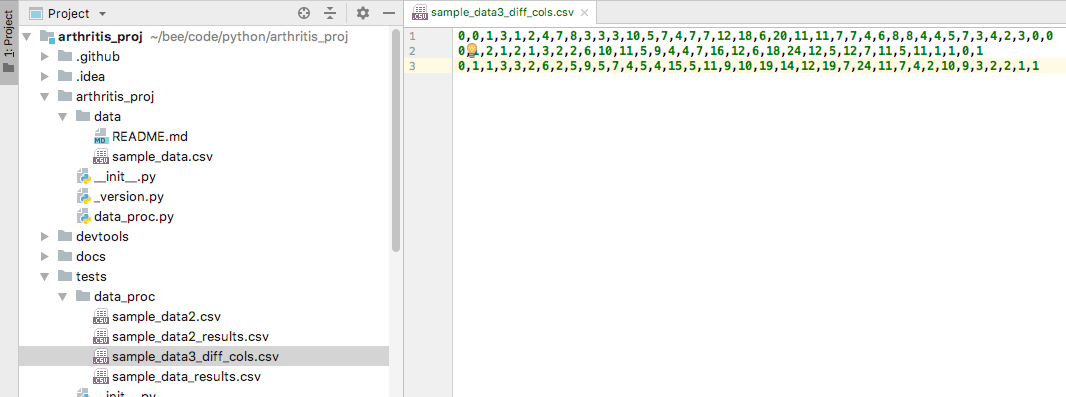
Let’s add another test together. I want to see what happens if I have different number of days of data for different patients. I started with a new file () in which I deleted some days of data from patients 2 and three (want to see what is different? Do a file compare!).
Screen shot
Now let’s see what happens when we run this, which I will do from the beginnings of a new test. Note that I moved a test into a new class. I do this to help people who might use my tests to figure out how to run the program.
In [9]:
class TestMainBadInput(unittest.TestCase):
def testMissingFile(self):
test_input = ["-c", "ghost.txt"]
main(test_input)
with capture_stderr(main, test_input) as output:
self.assertTrue("ghost.txt" in output)
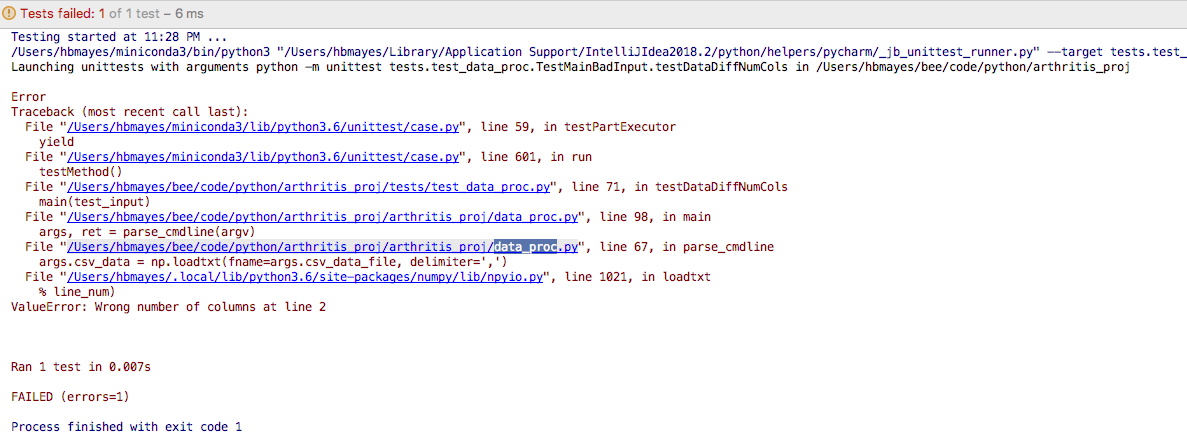
def testDataDiffNumCols(self):
input_file = os.path.join(TEST_DATA_DIR, "sample_data3_diff_cols.csv")
test_input = ["-c", input_file]
main(test_input)
Running testDataDiffNumCols, I get the following error:
Screen shot
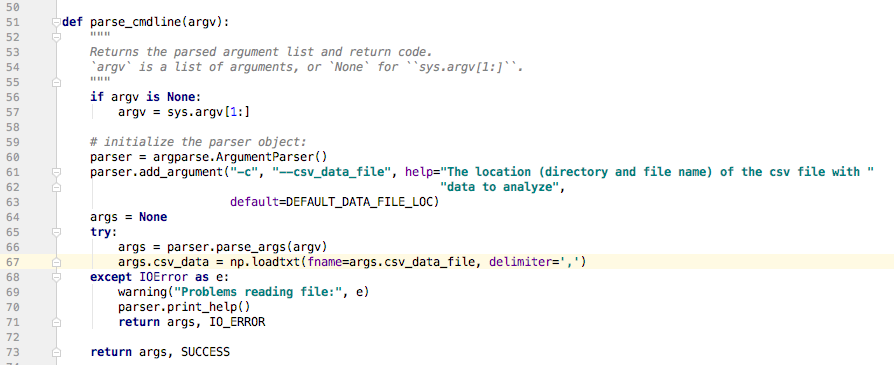
I’ll take this information, specifically the type of error that I’m getting, and do a try-catch loop for this error. I know that this problem happens in line 67 of data_proc.py, so I’ll go there (by clicking on the link) to see where I can catch this exception.
Screen shot
We are already in a try-catch loop, but it only caught an IOError.
We now can add the so I’ll add the ValueError.
In [10]:
def parse_cmdline(argv):
"""
Returns the parsed argument list and return code.
`argv` is a list of arguments, or `None` for ``sys.argv[1:]``.
"""
if argv is None:
argv = sys.argv[1:]
# initialize the parser object:
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--csv_data_file", help="The location (directory and file name) of the csv file with "
"data to analyze",
default=DEFAULT_DATA_FILE_LOC)
args = None
try:
args = parser.parse_args(argv)
args.csv_data = np.loadtxt(fname=args.csv_data_file, delimiter=',')
except IOError as e:
warning("Problems reading file:", e)
parser.print_help()
return args, IO_ERROR
except ValueError as e:
warning("Read invalid data:", e)
parser.print_help()
return args, INVALID_DATA
return args, SUCCESS
Let’s try running our test again.
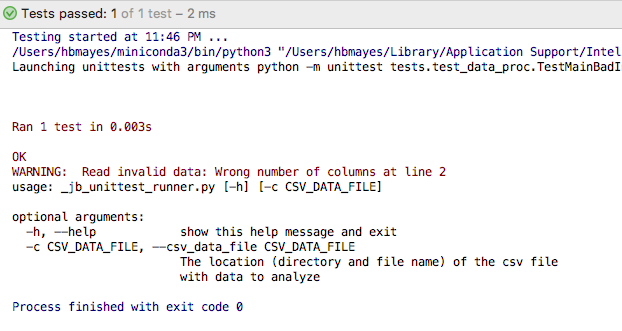
Screen shot
Now we get the behavior we want, but we are not yet actually testing anything with an assert statement. Let’s do that by checking that we get the error we expect. FYI: I added a clause that the program will be run on its own only if the debugger is on, but we are not getting anything from running it without capturing an error message that we will use for testing. It can be nice to see the whole output message, which we would get if we have make the debugging mode active.
In [11]:
class TestMainFailWell(unittest.TestCase):
def testMissingFile(self):
test_input = ["-c", "ghost.txt"]
if logger.isEnabledFor(logging.DEBUG):
main(test_input)
with capture_stderr(main, test_input) as output:
self.assertTrue("ghost.txt" in output)
def testDataDiffNumCols(self):
input_file = os.path.join(TEST_DATA_DIR, "sample_data3_diff_cols.csv")
test_input = ["-c", input_file]
if logger.isEnabledFor(logging.DEBUG):
main(test_input)
with capture_stderr(main, test_input) as output:
self.assertTrue("Wrong number of columns" in output)
Some best practices in writing tests¶
(from https://docs.python-guide.org/writing/tests/)
- A testing unit should focus on one tiny bit of functionality and prove it correct.
- Each test unit must be fully independent. Each test must be able to run alone, and also within the test suite, regardless of the order that they are called. The implication of this rule is that each test must be loaded with a fresh dataset and may have to do some cleanup afterwards.
- Try hard to make tests that run fast. If one single test needs more than a few milliseconds to run, development will be slowed down or the tests will not be run as often as is desirable. In some cases, tests can’t be fast because they need a complex data structure to work on, and this data structure must be loaded every time the test runs. Keep these heavier tests in a separate test suite that is run by some scheduled task, and run all other tests as often as needed. Use small versions of data and files to be tested to keep things fast.
- Learn your tools and learn how to run a single test or a test case. Then, when developing a function inside a module, run this function’s tests frequently, ideally automatically when you save the code.
- Always run the full test suite before a coding session, and run it again after. This will give you more confidence that you did not break anything in the rest of the code.
- It is a good idea to implement a hook that runs all tests before pushing code to a shared repository.
- If you are in the middle of a development session and have to interrupt your work, it is a good idea to write a broken unit test about what you want to develop next. When coming back to work, you will have a pointer to where you were and get back on track faster.
- The first step when you are debugging your code is to write a new test pinpointing the bug. While it is not always possible to do, those bug catching tests are among the most valuable pieces of code in your project.
- Use long and descriptive names for testing functions. The style guide here is slightly different than that of running code, where short names are often preferred. The reason is testing functions are never called explicitly. square() or even sqr() is ok in running code, but in testing code you would have names such as testSquareOfNumber2(), testSquareNegativeNumber(). These function names are displayed when a test fails, and should be as descriptive as possible.
- When something goes wrong or has to be changed, and if your code has a good set of tests, you or other maintainers will rely largely on the testing suite to fix the problem or modify a given behavior. Therefore the testing code will be read as much as or even more than the running code. A unit test whose purpose is unclear is not very helpful in this case.
- Another use of the testing code is as an introduction to new developers. When someone will have to work on the code base, running and reading the related testing code is often the best thing that they can do to start. They will or should discover the hot spots, where most difficulties arise, and the corner cases. If they have to add some functionality, the first step should be to add a test to ensure that the new functionality is not already a working path that has not been plugged into the interface.
Next steps¶
Start thinking about your project. I encourage discussion with me about what you might want to do and how to accomplish it. I will be posting some more examples to help you with the project; knowing what kinds of tasks you want to accomplish will help me set up useful examples for you.